A tree is a fundamental data structure in computer science that simulates a hierarchical structure, much like a family tree. It consists of nodes connected by edges, with one node acting as the root, and the rest branching out into child nodes. Trees are widely used in various algorithms, databases, and file systems due to their efficient data representation and manipulation capabilities. In this article, we will explore the key concepts, types, and operations associated with trees.
Table of Contents
Basic Concepts
A tree is a collection of entities called nodes. These nodes are connected via edges. The relationships between nodes are established in a hierarchical structure, starting with a single root node, and branching into child nodes.
Key Terminology:
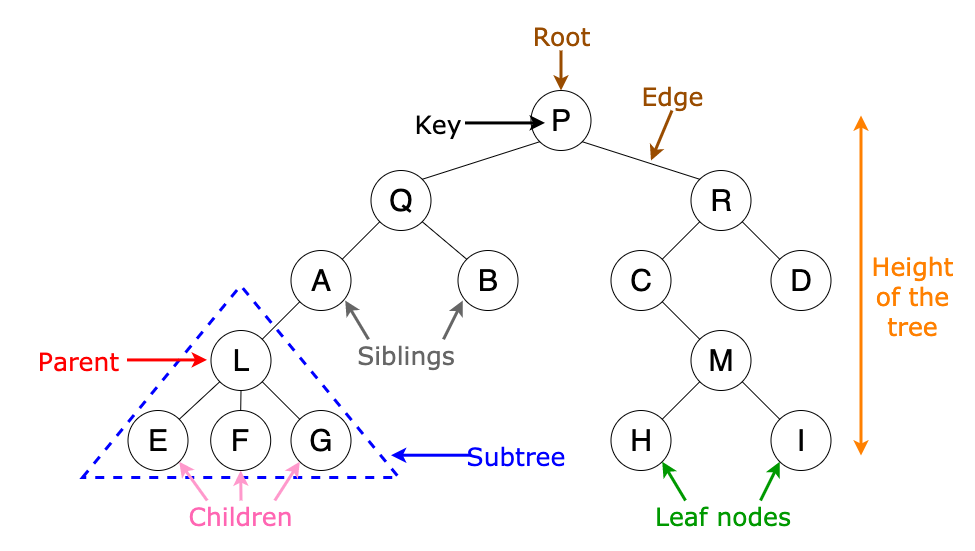
- Root: The topmost node in the tree. It has no parent node.
- Node: A fundamental part of the tree containing data and possibly links to child nodes.
- Edge: The connection between two nodes.
- Parent Node: A node that has one or more child nodes.
- Child Node: A node that descends from a parent node.
- Leaf Node: A node with no children.
- Subtree: A tree formed by a node and its descendants.
- Depth: The distance (number of edges) from the root node to a particular node.
- Height: The distance from a node to the deepest leaf in its subtree.
- Sibling: Nodes that share the same parent.
Properties of Trees
- Acyclic: Trees do not contain cycles. This means that there is no way to traverse from a node and come back to it by following the edges.
- Connected: All nodes in a tree are connected. There is a path between any two nodes in a tree.
- Single Root: Trees have only one root node. All other nodes are descendants of the root.
- N – 1 Edges: A tree with N nodes always has N−1 edges. This is a key property that differentiates trees from other graph structures.
Types of Trees
1. Binary Tree
A binary tree is a tree where each node has at most two children, referred to as the left child and the right child. This structure is frequently used in search algorithms and hierarchical data storage.
Properties:
- Each node can have 0, 1, or 2 children.
- Commonly used for binary search trees, heap structures, and expression trees.
2. Binary Search Tree (BST)
A Binary Search Tree is a type of binary tree where each node follows a specific ordering property: the left child of a node contains a value less than the node’s value, and the right child contains a value greater than the node’s value. This property makes searching, insertion, and deletion efficient.
Operations:
- Searching: O(h) where h is the height of the tree.
- Insertion and Deletion: O(h) on average, O(N) in the worst case.
3. Balanced Tree
A balanced tree is one where the height of the left and right subtrees of every node differs by no more than a certain factor (typically 1). Common examples include AVL Trees and Red-Black Trees.
Benefits:
- Ensures O(logN) time complexity for search, insertion, and deletion.
- Keeps the tree height minimal for efficient operations.
4. Heap
A heap is a special type of binary tree used in priority queues. Heaps maintain the property where the value of each node is greater (in a max-heap) or smaller (in a min-heap) than the values of its children.
5. Trie
A trie (pronounced “try”) is a type of tree used to store a dynamic set of strings. Tries are particularly useful for string manipulations like auto-completion and spell-checking.
Applications:
- Efficient string search operations.
- Often used in routing tables, text prediction systems, and word games.
Tree Traversals
Tree traversal refers to visiting all the nodes of a tree in a specific order. There are two main types of tree traversal:
1. Depth-First Traversal (DFT)
DFT explores a tree by going as deep as possible down one branch before backtracking. The most common types are:
- Preorder (Root → Left → Right): Visit the root first, then the left subtree, followed by the right subtree.
- Inorder (Left → Root → Right): Visit the left subtree, then the root, and then the right subtree. This traversal yields sorted values in a binary search tree.
- Postorder (Left → Right → Root): Visit the left and right subtrees first, and then the root.
2. Breadth-first traversal (BFT)
Also known as level-order traversal, this method visits nodes level by level from left to right. It uses a queue to traverse the tree layer by layer.
Common Operations on Trees
- Insertion: Adding a node to the tree while maintaining the specific ordering properties of the tree (e.g., binary search property for BSTs).
- Deletion: Removing a node and reorganizing the tree to maintain its structure and properties. Deletion in a binary search tree has three cases:
- Node is a leaf (no children).
- Node has one child.
- Node has two children (requires finding the in-order predecessor or successor).
- Searching: Finding a node with a particular value, with the efficiency depending on the type of tree (e.g., O(logN)O(\log N)O(logN) in balanced BSTs).
- Balancing: Adjusting the structure of the tree to ensure that the height remains small. This is crucial for maintaining efficient operations.
Applications of Trees
Trees are used in a wide range of real-world applications, including:
- File Systems: The hierarchical organization of directories and files is modeled as a tree.
- Databases: B-trees and B+ trees are used in databases for indexing to ensure efficient data retrieval.
- Compiler Design: Abstract syntax trees represent the structure of program code for compilers and interpreters.
- Artificial Intelligence: Decision trees are a popular method for decision-making processes in machine learning and AI.
- Networking: Routing algorithms often use spanning trees to determine the best paths in networks.
Conclusion
Trees are one of the most versatile and essential data structures in computer science. Their hierarchical nature and efficiency make them ideal for storing and manipulating structured data. Understanding tree operations and their various types is crucial for software developers, as trees are foundational in algorithms, databases, and many real-world applications. Whether it’s building a binary search tree for quick data lookups or leveraging a trie for efficient string operations, trees remain a powerful tool in a developer’s toolkit.
1 thought on “Understanding the Tree Data Structure”