Data structures are a core component of computer science, and understanding the right data structures for the task is crucial. This article will explore data structures and their practical real-life applications.
Table of Contents
Data structures are ways to organize and store data efficiently. Each data structure is built on top of more fundamental structures, and understanding the underlying mechanisms can help optimize their use.
Arrays
Definition
Arrays are one of the simplest data structures, consisting of elements stored at contiguous memory locations. They allow efficient access using an index and are widely used in scenarios where fast access to elements is crucial.
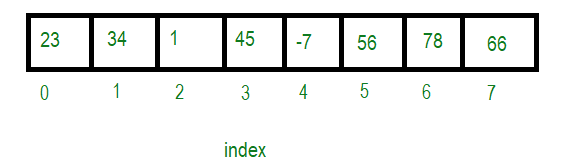
Implementation
Arrays are typically implemented using contiguous blocks of memory, where each element is stored at a fixed offset from the start of the array.
Real-Life Application
- Matrix, Grids, Vector
- The array is used to present matrices, grids, vectors, tables etc
- Games based on grids like Chess, Sudoku, Ludo etc
- Matrix operations are performed using array representation
- Excel and Google sheet have grid structures, which are easily represented by arrays
- Lookup tables
- Image processing:
- Arrays are used to represent images, where each element of the arrays corresponds to a pixel
- Manipulating arrays allows operations like scaling, rotating blurring, sharpening and applying filters
- Continuous Data
- Data produced by Iots senors like temperate, humidity etc and efficiently stored using arrays
- Arrays are used in buffers for real-time streaming, such as in video or audio applications. Data is temporarily stored in an array buffer before being processed, allowing for smooth streaming without interruption.
- Listing
- Todo list
- Contacts
- Product listing on e-commerce sites
- Stock Management
- Task scheduler in operating systems uses arrays to keep track of tasks and their states
Linked List
Definition
Linked lists are a linear collection of nodes, where each node points to the next. This structure enables efficient insertion and deletion of elements without shifting other elements.
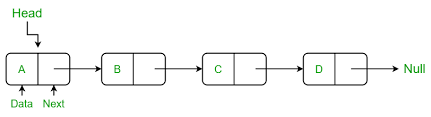
Implementation
A linked list consists of nodes where each node contains data and a reference (or pointer) to the next node.
Real-Life Application
- Implementing stacks and queues
- Linked lists can be used to implement both stacks and queues. Since linked lists allow dynamic memory allocation and flexible size management, they are a natural fit for building stacks (LIFO) or queues (FIFO) with fast insertion and removal operations.
- Undo and redo functionality in applications
- Test editors, graphics software
- Backward and forward navigation
- Browser history: doubly linked lists enable efficient navigation in both directions by maintaining pointers to the previous and next nodes.
- Playlists: Many Music/Video players use linked lists to store and navigate songs
- Sequential Photo Browsing: Photo viewers often use doubly linked lists to allow users to navigate between photos in a gallery. Each photo is a node in the list, with next and previous pointers to navigate through the photo collection.
- Memory Management in dynamic allocation
- Operating Systems use linked lists to manage free and allocated memory blocks in operating systems. For example, the memory allocator maintains a linked list of free memory blocks, efficiently managing memory allocation and deallocation requests from running programs.
- Representation
- Graph representation: Linked lists are used to represent sparse graphs efficiently. In an adjacency list representation, each node (vertex) has a linked list that contains all the nodes it is connected to, providing an efficient way to store relationships in large networks like road maps or social networks.
- Polynomial Manipulation: Linked lists are used to store polynomials in which each node represents a term. This allows for efficient manipulation of polynomials, such as addition, subtraction, and multiplication, where terms can be dynamically added or removed as necessary.
- Sparse Matrix Representation: In applications where matrices are large but contain mostly zero elements (such as scientific computing or image processing), linked lists are used to store only the non-zero elements in an efficient way, saving memory and reducing computational overhead.
- Real-Time Multiplayer Games: Linked lists are used in multiplayer games to keep track of players in a game room. As players join or leave, the list can dynamically adjust, allowing for efficient insertion or removal of players.
- CPU Job Scheduling: In multitasking operating systems, a circular linked list can be used to manage the processes that need to run. The scheduler moves through the list, allocating CPU time to each process, and once a process has finished its execution time, it cycles back to the start of the list.
- Implementation of Least Recently Used (LRU) Cache: Doubly linked lists are used in the implementation of LRU caching algorithms. The cache keeps track of the most recently accessed elements and uses a linked list to efficiently move elements to the front (most recently used) or remove elements from the back (least recently used).
- Hash Map with Chaining: Linked lists are often used in hash maps to handle collisions. When multiple elements are hashed to the same index, the elements are stored in a linked list at that index, allowing for dynamic resolution of hash collisions.
Stacks
Definition
Stacks follow the Last-In-First-Out (LIFO) principle. The last element added to the stack is the first to be removed, making stacks ideal for scenarios involving nested or sequential tasks.

Implementation
Stacks can be implemented using either arrays or linked lists.
Real-Life Application
- Undo/Redo Operations
- Application: Text Editors, Image Manipulation Tools
- Stacks are used to implement undo/redo functionality in software. For example, when a user performs an action (e.g., typing a character), it’s pushed onto the undo stack. To undo the action, the last item is popped from the stack and moved to the redo stack, allowing reversible operations.
- Expression Evaluation
- Infix, Prefix, and Postfix Expressions
- Stacks are used to evaluate arithmetic expressions in programming languages. For example, converting an infix expression (e.g., (A + B)) into a postfix or prefix allows the system to process it more efficiently, and stacks are integral in parsing and evaluating these expressions.
- Backtracking Algorithms
- Application: Solving Mazes, Puzzles (e.g., Sudoku, N-Queens Problem)
- Stacks are used in backtracking algorithms, which explore all possibilities by trying one solution path and pushing it onto the stack. If it leads to a dead end, the system backtracks by popping the current state from the stack and trying a different path.
- Function Call Management (Recursion)
- Application: Function Calls and Recursion Handling
- When a function calls another function (or recursively calls itself), the current function’s state (parameters, return address, local variables) is pushed onto a stack. When the called function completes, its state is popped from the stack, allowing the program to resume where it left off.
- Syntax Parsing
- Application: Compilers and Expression Parsing
- Compilers use stacks during syntax parsing of programming languages to check for matching parentheses, brackets, and other paired tokens. When an opening parenthesis is encountered, it’s pushed onto the stack; when a closing one is encountered, the stack is popped to ensure proper nesting.
- Parenthesis Matching
- Application: Expression Balancing in Code and Mathematical Formulas
- Stacks are used to check for balanced parentheses in expressions, ensuring that each opening parenthesis has a corresponding closing one. This application is essential in programming language parsers and editors to ensure valid code.
- Memory Management
- Application: Call Stack in Operating Systems
- Stacks are used in memory management to track function calls in the form of a call stack. The stack grows and shrinks as functions are called and return, efficiently managing memory for local variables and parameters.
- Tree Traversal
- Application: Depth-First Search (DFS)
- Stacks are used in the implementation of the depth-first search algorithm for traversing trees and graphs. DFS explores as far as possible along one branch before backtracking, which is naturally supported by a stack data structure.
- Expression Conversion (Infix to Postfix)
- Application: Compiler Design and Mathematical Expression Solvers
- Stacks are used in algorithms to convert expressions from infix (human-readable) to postfix (machine-readable) format. This conversion simplifies the evaluation of complex mathematical expressions in compilers.
- Palindrome Checking
- Application: Detecting Palindromes in Strings
- Stacks can be used to check whether a string is a palindrome (i.e., it reads the same forwards and backwards). By pushing the first half of the string onto a stack and then comparing it with the second half, palindromes can be detected.
- Virtual Machine and Emulator Execution
- Application: Stack-based Virtual Machines (e.g., Java Virtual Machine)
- Virtual machines like the Java Virtual Machine (JVM) or the Python interpreter use stacks to manage operations and operands. In these machines, instructions are pushed onto a stack and popped off during execution.
- Balanced Symbol Checking
- Application: HTML/XML Parsing
- When parsing HTML or XML documents, stacks are used to ensure that tags are properly nested. The opening tags are pushed onto the stack, and as closing tags are encountered, they are popped off to check for valid structure.
- Expression Evaluation in Calculators
- Application: Reverse Polish Notation Calculators
- Stack-based calculators (those using postfix notation) evaluate mathematical expressions by pushing numbers onto a stack and applying operators as they are encountered. This method avoids the need for parentheses, making the computation faster.
- Operating System Process Management
- Application: Multithreading and Process Scheduling
- In multithreading environments, stacks are used to store the execution context of threads. Each thread has its own stack where local variables and function calls are stored, enabling efficient switching between threads.
- Directory Traversal in File Systems
- Application: Recursive Directory Listings
- Stacks are used for exploring directories recursively. When listing files in a directory, subdirectories are pushed onto the stack to be explored later, mimicking depth-first search behaviour.
Queues
Definition
Queues operate on a First-In-First-Out (FIFO) basis, where elements are added to the rear and removed from the front. They are used in systems where processing occurs in the order of arrival.
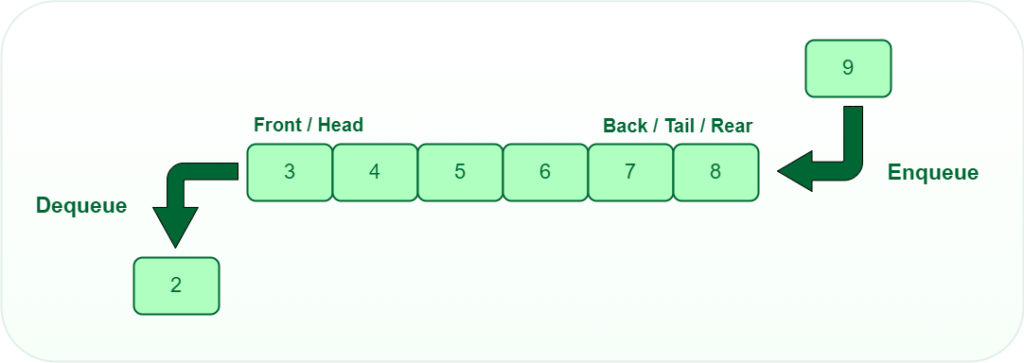
Implementation
Like stacks, queues can be implemented using arrays or linked lists.
Real-Life Application
- Task Scheduling in Operating Systems
- Application: Queues manage processes in operating systems.
- For example, in a multitasking operating system, processes are scheduled using queues like a Round-Robin scheduling algorithm where each task gets a time slice in a cyclic order, ensuring all tasks are processed fairly.
- Print Spooling
- Application: When multiple print jobs are sent to a printer, they are stored in a queue, waiting their turn to be printed in the order they were received. This prevents jobs from being lost or skipped and ensures that each job is printed sequentially.
- Breadth-First Search (BFS) in Graphs
- Application: BFS uses a queue to explore nodes level by level in a graph. It is used in applications such as:
- Shortest Path Algorithms (e.g., in navigation systems like Google Maps)
- Web Crawling, where websites are visited in layers to avoid missing links at any depth.
- Customer Service Systems (Banking, Ticketing)
- Application: In customer service systems (like banks or airline ticketing counters), customers are placed in a queue and served in the order they arrive. This ensures fairness and avoids chaos in high-traffic service areas.
- Buffering in Streaming Media
- Application: Queues are used in streaming applications like YouTube or Netflix to buffer data packets before they are displayed to the user. The queue ensures that media is played smoothly, even if there are fluctuations in the data transfer rate.
- Network Routers and Switches
- Application: Queues are used in routers and switches to handle incoming and outgoing data packets. Packets are queued until they can be processed or forwarded, ensuring that data is transmitted in an orderly and reliable manner.
- Call Handling Systems
- Application: In call centres, queues manage incoming phone calls. Calls are answered in the order they arrive, ensuring that no customer is skipped or ignored. This is a critical feature in managing customer satisfaction during high-volume periods.
- Data Processing Pipelines
- Application: In distributed data processing systems like Apache Kafka or Amazon SQS, queues are used to manage streams of data between producers and consumers. This allows systems to handle a large volume of data and distribute processing tasks among multiple workers efficiently.
- Real-Time Event Processing (IoT Systems)
- Application: Queues handle real-time events in IoT systems, such as sensor data from connected devices. The data is queued and processed in order, ensuring that no event is missed and processed in the correct sequence.
- Paging Systems (Virtual Memory Management)
- Application: In virtual memory management, queues are used to implement page replacement algorithms like FIFO, where pages are swapped in and out of memory. This ensures efficient memory utilization and avoids thrashing.
- Job Queues in Cloud Computing
- Application: In cloud environments, queues manage asynchronous tasks such as image processing, video transcoding, and large data uploads. Queues allow these tasks to be processed independently of the main application flow, improving scalability.
- Load Balancers
- Application: In distributed systems, queues are used in load balancers to manage incoming requests and distribute them across multiple servers. This ensures that the servers process requests evenly and prevents overload on any one server.
- Priority Queues for Emergency Services
- Application: In hospitals or emergency services, patients or incidents are managed using priority queues. Critical cases (like life-threatening conditions) are given higher priority and processed first, even if they arrive later than less critical cases.
Hash Tables
Definition
Hash tables (or hash maps) store key-value pairs and allow efficient data retrieval based on unique keys. They provide average-case constant time complexity for lookups and inserts.
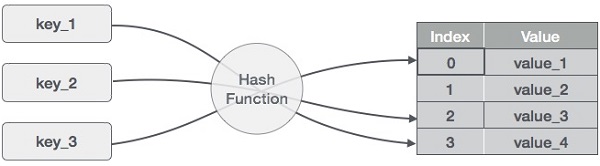
Implementation
Hash tables are built on arrays. They use a hash function to map keys to array indices. When collisions occur (multiple keys map to the same index), strategies like chaining (using linked lists) or open addressing (linear or quadratic probing) are employed.
Real-Life Application
- Database Indexing
- Hash tables are extensively used in databases to index records, making it easier to retrieve customer data or transactions by using unique keys like customer IDs.
- Caching Systems
- Application: Web Browsers and Servers
- Hash tables are used to store cached web pages, images, or other frequently accessed resources. When you visit a website, a browser caches the content using a hash table to quickly retrieve it without reloading it from the server.
- Symbol Table in Compilers
- Application: Variable Lookup
- Compilers use hash tables to store variable and function names as symbols. When translating source code, the compiler quickly looks up variables in the symbol table to check for declarations, saving time during the compilation process.
- Blockchain and Cryptography
- Application: Transaction Management
- In blockchain systems, hash tables are employed to manage transactions efficiently, especially for storing user account balances and transaction history. Cryptographic hashes are also used in mining and securing the blockchain.
- Load Balancing
- Application: Distributing Requests
- Hash tables are used in distributed systems to evenly distribute requests among multiple servers. The hash of the request (like an IP address) determines which server will handle the request, ensuring balanced load distribution.
- DNS Resolution
- Application: Domain Name Lookup
- The Domain Name System (DNS) uses hash tables to resolve domain names into IP addresses. Hashing speeds up the process of finding the corresponding IP for a domain, making web browsing faster.
- Routing Tables in Networks
- Application: Packet Forwarding
- Routers use hash tables in their routing tables to determine the next hop for data packets. The hash of an IP address is used to look up the forwarding information, speeding up the routing process.
- Spell Checkers
- Application: Word Lookup
- Hash tables store dictionaries of correctly spelled words. When a user types a word, it is hashed and checked against the table to determine if it’s spelled correctly. This speeds up the spell-checking process.
- Counting Frequencies
- Application: Data Analysis
- Hash tables are often used in data analysis to count the frequency of items. For instance, they can be used to count the occurrence of words in a document or items sold in an e-commerce platform.
- File Systems
- Application: Metadata Storage
- Some file systems use hash tables to manage file metadata, allowing quick access to file attributes like permissions, timestamps, and sizes. This is particularly useful in distributed file systems.
- Content Deduplication
- Application: Cloud Storage Optimization
- Cloud storage providers use hash tables for deduplication, which helps in storing only one copy of duplicate files. A hash is created for each file, and duplicate files are identified and eliminated by matching the hash values.
- Word Games (Scrabble, Crosswords)
- Application: Fast Word Lookup
- In games like Scrabble or crossword puzzles, hash tables are used to quickly check if a combination of letters forms a valid word, ensuring quick gameplay without lag.
- Authentication Systems
- Application: Password Management
- Authentication systems store hashed versions of passwords using hash tables. When a user logs in, the entered password is hashed and compared to the stored hash, enhancing security and speeding up the authentication process.
- Artificial Intelligence (AI) and Machine Learning
- Application: Feature Hashing
- Hashing is used in AI/ML models to represent high-dimensional data efficiently. For example, hash tables are used to convert text or categorical data into numerical features during the feature engineering process.
Tree
Definition
Trees are hierarchical structures where each node has child nodes, forming a parent-child relationship. They are used to represent systems with hierarchical relationships.
Implementation
Binary trees are typically implemented using nodes that contain data and two pointers
Real-Life Application
- File Systems
- Trees are fundamental in file systems where directories act as nodes and files as leaves. This hierarchical structure simplifies the navigation and organization of data.
- Binary Search Tree (BST)
- Application: Efficient Searching and Sorting
- Binary Search Trees (BSTs) are used in search engines, databases, and file systems to organize and retrieve data efficiently. They allow for fast insertion, deletion, and search operations, particularly when balanced.
- Trie (Prefix Tree)
- Application: Routing Tables in Networks
- Tries are used to implement routing tables in computer networks. Each node in a trie can represent a part of an IP address, and they help in determining the next hop for data packets.
- Decision Tree
- Application: Machine Learning
- Decision trees are a widely used machine learning algorithm for classification and regression tasks. They work by splitting data based on feature values and forming a tree structure to make decisions.
- Example: In credit scoring, a decision tree could help classify whether a loan applicant is a high or low risk based on factors like income, employment status, and credit history.
- Merkle Tree
- Application: Blockchain and Cryptography
- Merkle trees are used in blockchain technology for efficient and secure verification of data. They enable fast validation of large data structures by storing data hashes in tree nodes.
- Example: Bitcoin and other cryptocurrencies use Merkle trees to verify transactions across blocks without needing to store all transaction data.
- Game Tree
- Application: Artificial Intelligence in Games
- Game trees are used in AI for strategy games like chess and Go. These trees represent possible moves, with each node corresponding to a game state. AI algorithms explore these trees to choose optimal moves.
- Example: The AI in chess engines like Stockfish uses game trees to predict future moves and determine the best possible strategy.
- Expression Tree
- Application: Compilers and Expression Parsing
- Expression trees represent mathematical expressions, where the leaves are operands (constants or variables) and internal nodes are operators (like +, *, /). They are used in compilers to evaluate expressions.
- Example: Expression trees are used in the parsing phase of compilers to break down and evaluate mathematical formulas or code expressions.
- Heap (Binary Heap)
- Application: Dynamic Memory Allocation
- Heaps are used to implement priority queues in operating systems, which are essential for managing dynamic memory allocation. The heap ensures that the highest priority process is allocated memory first.
- Example: Memory managers in operating systems use heaps to allocate and free blocks of memory dynamically for running programs.
- Parse Tree (Syntax Tree)
- Application: Natural Language Processing (NLP)
- Parse trees, or syntax trees, are used in NLP to represent the grammatical structure of sentences. These trees break down sentences into parts of speech and syntactical relations.
- Example: Chatbots and language models use parse trees to understand and process user input, improving the quality of responses by analyzing sentence structure.
- Spanning Tree
- Application: Network Design
- Spanning trees are used in networking to ensure there are no loops in a network. They help in designing minimal, loop-free network topologies and are used in protocols like the Spanning Tree Protocol (STP).
- Example: STP prevents loops in Ethernet networks by constructing a spanning tree and ensuring only the best paths are used for data transmission.
- Suffix Tree
- Application: String Searching and Data Compression
- Suffix trees are used for fast substring search operations, as well as for data compression algorithms. They store all suffixes of a given string, allowing for quick pattern matching.
- Example: DNA sequence analysis uses suffix trees to efficiently search for patterns in long genetic sequences, helping researchers identify specific gene mutations.
- KD-Tree (K-Dimensional Tree)
- Application: Nearest Neighbor Search in Machine Learning
- KD-trees are used in algorithms for nearest neighbour search in machine learning, computer graphics, and spatial data analysis.
- Example: In machine learning, KD trees can be used to efficiently find the nearest neighbors of data points in high-dimensional datasets, aiding in classification tasks.
- QuadTree
- Application: Spatial Partitioning in Computer Graphics
- Quadtrees are used in computer graphics to partition a 2D space into smaller sections, which optimizes rendering processes by focusing only on relevant sections of a scene.
- Example: In video games, quadtrees are used to manage spatial partitioning for collision detection, ensuring that objects only check for collisions with nearby elements.
- Interval Tree
- Application: Interval Overlap Queries
- Interval trees are used to efficiently handle queries related to intervals, such as finding overlapping intervals or checking if a given interval is contained within another.
- Example: Interval trees are used in scheduling systems to check for conflicts between appointments or tasks with overlapping time slots.
- B-Tree
- Application: Disk-Based Storage Systems
- B-trees are used in databases and file systems to store large amounts of data in a balanced manner, ensuring that search, insert, and delete operations are performed efficiently even when the data doesn’t fit in memory.
- Example: B-trees are commonly used in database management systems like MySQL and PostgreSQL to index large datasets, enabling fast queries.
- R-Tree
- Application: Geographic Information Systems (GIS)
- R-trees are used to index multi-dimensional spatial data, such as maps. They allow for efficient querying of spatial regions, including proximity and overlap queries.
- Example: GIS systems use R-trees to store geographical features (like roads, rivers, and boundaries) and to optimize spatial queries related to location-based services.
- Fenwick Tree (Binary Indexed Tree)
- Application: Cumulative Frequency Tables
- Fenwick trees are used to compute cumulative frequencies and updates efficiently, useful in various statistical and financial applications.
- Example: Fenwick trees are used in calculating moving averages in stock price analysis, enabling quick updates and range queries.
- Phylogenetic Tree
- Application: Evolutionary Biology
- Phylogenetic trees represent evolutionary relationships between species or genes, helping scientists trace the lineage of organisms over time.
- Example: Researchers use phylogenetic trees to map the evolutionary history of organisms and to study how species are related based on their genetic information.
Graphs
Definition
Graphs consist of nodes connected by edges and are used to model complex relationships between entities, such as social or transport networks.
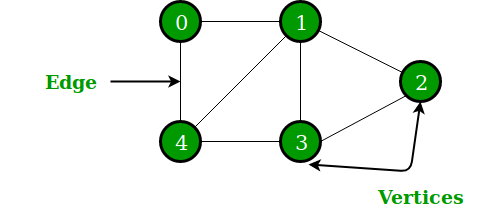
Implementation
- Adjacency Matrix: Uses a 2D array to store whether an edge exists between pairs of vertices. This is efficient for dense graphs but consumes O(V^2) space.
- Adjacency List: Uses an array of lists, where each vertex has a list of its adjacent vertices. This is space-efficient for sparse graphs and allows O(V + E) traversal.
Real-Life Application
- Social Networks
- Social media platforms use graphs to represent users and their connections. Each user is a node, and their relationships are edges connecting them to other users.
- Web Page Ranking (Google’s PageRank Algorithm)
- Application: Search engines like Google use graphs to represent the internet, where each webpage is a node, and hyperlinks between pages are the edges. The PageRank algorithm assigns importance to pages based on their incoming links, helping search engines rank results for a query.
- Routing Algorithms (GPS and Internet)
- Application: Graphs are used extensively in GPS navigation systems and the Internet to model networks of roads or data connections. Nodes represent locations or devices, and edges represent paths or network connections. Algorithms like Dijkstra’s or A search* find the shortest path between two points, ensuring efficient routing.
- Recommendation Systems (Movies, Products, etc.)
- Application: Graphs are used in recommendation systems on platforms like Netflix, Amazon, and Spotify. Nodes represent users and items (movies, songs, products), and edges connect users to items they have interacted with. Collaborative filtering and graph traversal algorithms help suggest new items based on user preferences and connections to other users or items.
- Dependency Resolution (Package Managers)
- Application: Package managers like npm (for JavaScript) or apt (for Linux) use graphs to model the dependencies between software packages. Nodes represent packages, and edges represent dependencies. The graph helps the system resolve dependencies when installing or updating packages, ensuring that all required software components are correctly installed.
- Knowledge Graphs (Semantic Web)
- Application: Knowledge graphs model relationships between concepts or entities, such as in Google Knowledge Graph. Nodes represent entities like people, places, or events, and edges represent relationships like “is a sibling of” or “was born in.” These graphs enable smarter search engines and AI systems by connecting and reasoning over related concepts.
- Game Theory (Game Trees and Strategy Graphs)
- Application: In game theory and AI for games, graphs are used to model decision-making scenarios. Game trees represent different possible moves in games like chess or Go, where nodes represent game states, and edges represent possible moves. AI algorithms like Minimax or Monte Carlo Tree Search traverse these trees to find the optimal strategy.
- Airline and Railway Networks
- Application: Airlines and railway systems use graphs to model routes and connections between cities or stations. Nodes represent cities or stations, and edges represent direct routes or flights. Algorithms help optimize routing, minimize travel time, or handle network disruptions efficiently.
- Compiler Design (Control Flow and Data Flow Graphs)
- Application: In compiler design, control flow graphs and data flow graphs are used to represent the flow of control and data through a program. Nodes represent basic blocks of code, and edges represent possible transitions between them. These graphs help optimize code, detect dead code, and perform other optimizations during compilation.
- Image Segmentation (Computer Vision)
- Application: In computer vision, graphs are used to represent pixels or regions in an image for image segmentation. Each node represents a pixel or region, and edges represent relationships (e.g., colour similarity or proximity). Graph-cut algorithms help partition the image into meaningful segments, such as identifying objects in a scene.
- Causal Inference (Bayesian Networks)
- Application: In statistics and machine learning, graphs are used to model probabilistic relationships between variables in systems like Bayesian Networks. Nodes represent variables, and edges represent causal dependencies. These models help in making predictions and understanding causal relationships between variables.
- Telecommunications Networks
- Application: Telecommunication companies use graphs to represent communication networks, where nodes represent phones, computers, or data centres, and edges represent communication links. Graph algorithms are used to optimize routing, balance loads, and ensure the reliability of communication.
- Peer-to-Peer Networks (P2P File Sharing)
- Application: In peer-to-peer (P2P) file-sharing systems like BitTorrent, graphs are used to model the network of peers. Each node represents a peer (a user sharing files), and edges represent file-sharing connections. Efficient graph traversal and search algorithms help users find the files they want to download.
- Smart Grids (Energy Distribution)
- Application: In smart grids, graphs model the distribution of electricity where nodes represent energy sources (power plants) and consumers (homes, industries), and edges represent power lines. Graph algorithms optimize energy flow, detect outages, and ensure load balancing across the grid.
Heaps
Definition
A heap is a specialized tree-based structure used primarily to implement priority queues. It ensures that the highest (or lowest) priority element is always at the root.

Real-Life Application
- Priority Queues
- priority queues are used for job scheduling
- Heapsort
- Heaps are used in Heapsort, a comparison-based sorting algorithm with time complexity of O(nlogn). It is particularly useful in scenarios where constant space complexity is required, as Heapsort works in place.
- Dynamic Median Finding
- Application: Real-Time Data Streams
- Heaps are used to efficiently track the median of a dynamic data stream by maintaining two heaps: a max-heap for the lower half of the data and a min-heap for the upper half. This approach is crucial in financial data analysis or online services where real-time median tracking is required.
- Median of Running Data
- Application: Real-Time Stock Trading Systems
- In financial markets, heaps help compute the median price in real-time as new transactions occur. This is crucial in building algorithms for portfolio management and price prediction models.
- Data Compression
- Application: Huffman Coding
- Huffman coding, used in data compression algorithms like ZIP and JPEG, employs heaps to build the Huffman tree. A min-heap is used to repeatedly extract the two smallest frequency elements to generate the optimal binary code tree for compression.
- Merging K-Sorted Lists
- Application: Database Merging
- When merging multiple sorted lists (e.g., from different database shards), a min-heap can be used to efficiently extract the smallest element from the heads of all lists, maintaining the sorted order with minimal overhead. This is useful in scenarios like database joins or combining search results.
Sets
Definition
Sets store unique elements and provide fast membership checking, ensuring no duplicate elements are stored.
Implementation
Sets are often implemented using hash tables for efficient lookup, insertion, and deletion.
Real-Life Application
- Duplicate removal
- Sets are used to eliminate duplicate records from large datasets, such as when processing customer data or cleaning up lists of unique identifiers.
- Application: Websites like blogs, e-commerce platforms, or social media use sets to manage tags. Each item (e.g., blog post, product) can have multiple associated tags and sets to ensure that no duplicate tags are assigned to an item.
- Venn Diagrams and Set Operations
- Application: Sets relate to mathematical concepts like union, intersection, and difference. These operations are heavily used in data science, marketing analytics, and more.
- Example: A marketing team might use sets to analyze customer overlap between different product categories. For example, they can identify common buyers by performing an intersection of two sets (customers who bought Product A and Product B).
- Handling Large Data Streams
- Application: Sets are useful in dealing with data streams where duplicates need to be eliminated or certain elements need to be filtered out on the fly.
- Example: In network traffic monitoring, sets can be used to track unique IP addresses to prevent duplicate or malicious traffic from being processed.
Dictionaries (Hash Maps)
Definition
Dictionaries store key-value pairs, allowing for fast retrieval of values based on their keys.
Implementation
Like sets, dictionaries (or hash maps) are implemented using hash tables where each key-value pair is stored. The hash function determines where the key-value pair is stored in an underlying array, and collisions are handled similarly to hash tables.
Real-Life Application
- It is a common data structure to save application configurations, user profiles etc
Trie
Definition
A Trie is a tree-like data structure used to store strings where each node represents a character. It is commonly used for prefix-based operations.
Real-Life Application
- Autocomplete and spell checkers
- Tries power the auto-complete functionality in search engines and mobile keyboards, allowing for fast retrieval of words that share common prefixes.
- Digital dictionaries or spelling correction tools use tries to efficiently store and retrieve words, allowing for fast word lookups and providing suggestions for misspelled words.
- Autocomplete for Code Editors
- Auto-Correction in Messaging Apps
- Search Engines’ Query Suggestion
- DNS Lookups
- Application: Domain Name Systems (DNS) use tries to resolve domain names into IP addresses. Tries help in storing hierarchical domain names (like www.example.com) and quickly retrieving associated IPs.
- Pattern Matching in Text
- Application: Tries are used in text processing tasks like finding the occurrence of a pattern in a large text. The Aho-Corasick algorithm, used for multi-pattern matching, builds on the trie structure for efficient matching.
- T9 Predictive Text
- Application: Early mobile phones used T9 predictive text input, which relies on tries to map numeric keypad presses to possible word suggestions. The trie helps predict the most likely word based on a sequence of keypresses.
- Word Search Puzzles
- Application: Tries are employed in algorithms that solve word search puzzles. By storing a dictionary in a trie, search algorithms can efficiently check if a word exists in a large grid of letters.
- Product Search in E-commerce
- Application: E-commerce websites use tries for their search functionality. When users type product names in the search bar, tries can quickly suggest items based on the entered prefix, improving search response time.
Bloom filter
Definition
A Bloom filter is a probabilistic data structure used to test whether an element is a member of a set, with a possibility of false positives.
Real-Life Application
- Web Caching: Efficient URL Cache Lookup
- Bloom filters are used in web caching systems to determine whether a particular URL is in the cache. Before performing an expensive cache lookup, a Bloom filter quickly checks if the URL might be in the cache. If the filter indicates a potential hit, the system proceeds with the actual lookup.
- In content distribution networks (CDNs) like Akamai, Bloom filters help servers quickly check whether a particular file is cached locally or needs to be fetched from a distant server. This enhances the efficiency of content delivery to end users.
- Database Query Optimization
- Application: Filtering Non-Existent Rows
- In distributed databases, Bloom filters help reduce the need to query multiple nodes by filtering out non-existent rows. For instance, in databases like Apache Cassandra and Google Bigtable, Bloom filters quickly check whether a particular row or data entry might exist on a node, avoiding unnecessary disk I/O.
- Email Spam Filtering
- Application: Filtering Out Known Spam Senders
- Email systems use Bloom filters to store the signatures of known spam email senders. When new emails arrive, the system quickly checks if the sender might be in the spam list using the Bloom filter before performing more computationally expensive checks.
- Distributed Hash Tables (DHTs)
- Application: Membership Testing in Peer-to-Peer Networks
- In peer-to-peer networks like BitTorrent, Bloom filters are used to quickly check if a file or key is present in a distributed hash table (DHT) without querying the entire network, reducing bandwidth usage and latency.
- Filesystem Deduplication
- Application: Eliminating Duplicate Files
- Filesystem deduplication tools use Bloom filters to track file signatures and detect potential duplicates. This enables quick identification of whether a file or data block has already been stored, reducing redundant storage.
Count min sketch
Definition
The Count-Min Sketch (CMS) is a probabilistic data structure used for counting frequency distributions of elements in data streams with limited memory usage. It allows approximate querying of frequencies with a small error margin and is particularly useful in big data scenarios where storing all data would be infeasible.
Real-Life Application
- Network Traffic Monitoring
- Application: Detecting Heavy Hitters
- In large networks, CMS is used to monitor packet streams and identify “heavy hitters” — IP addresses or flows that generate large amounts of traffic. By approximating the count of packets or requests associated with each IP, network administrators can detect potential denial-of-service (DDoS) attacks or misbehaving users without storing every single packet.
- Web Analytics
- Application: Tracking Popular Pages or Queries
- CMS helps track the most frequently accessed web pages, search queries, or advertisements in real time on large platforms like Google, Facebook, or YouTube. Since it uses less memory, it can efficiently monitor click-through rates or search terms in high-traffic environments while providing approximate counts of user interactions.
- Database Query Optimization
- Application: Approximate Join Cardinality Estimation
- CMS is used in databases to estimate the number of unique records or the result size of a join operation, helping optimize query execution plans. Instead of scanning entire datasets, CMS gives quick, space-efficient estimations of frequency counts for different attributes in a dataset.
- Real-Time Recommendation Systems
- Application: Counting Item Popularity
- Recommendation engines (e.g., for e-commerce platforms like Amazon or streaming services like Netflix) use CMS to maintain frequency counts of item views, clicks, or purchases. By tracking which products or movies are popular in real time, CMS helps systems provide personalized recommendations to users with minimal memory overhead.
- Spam Detection in Email Services
- Application: Tracking Spammy Senders
- CMS is used to detect senders with unusually high email volumes, which could be an indication of spam. By approximating the frequency of emails from various senders, it helps identify potential spammers while minimizing the storage footprint in large-scale email services.
- Load Balancing in Distributed Systems
- Application: Counting Task Frequencies
- In distributed systems, CMS is used to track the number of times tasks or queries are executed on specific servers. This allows the system to balance the load more efficiently by ensuring that heavily used resources are monitored and redirected appropriately, preventing bottlenecks.
- Fraud Detection in Payment Systems
- Application: Detecting Unusual Transaction Patterns
- Payment systems use CMS to track the frequency of transactions associated with accounts, IP addresses, or credit cards. When unusual patterns or spikes in transaction volume are detected, it helps flag potentially fraudulent behaviour without storing all transaction data.
- Search Engine Query Frequency
- Application: Tracking Query Trends
- Search engines like Google use CMS to track the frequency of search terms in real time, providing insights into trending topics or popular queries. This helps the engine serve better suggestions and advertisements to users based on current trends, all while using limited memory.
- Distributed Cache Management
- Application: Tracking Popular Cache Entries
- In large distributed cache systems (e.g., Memcached or Redis), CMS helps track which cache keys are accessed most frequently. This enables cache replacement algorithms to prioritize retaining frequently accessed data and efficiently manage memory in large-scale applications.
- Content Delivery Networks (CDNs)
- Application: Tracking Content Popularity
- CDNs use CMS to monitor which pieces of content (like videos, images, or webpages) are being accessed the most in real time. Based on these approximate counts, CDNs can optimize content distribution and load balancing, ensuring that popular content is served from servers closest to users.
- Security and Intrusion Detection
- Application: Counting Malicious Activities
- Security systems use CMS to track unusual behaviour patterns such as login attempts, data access requests, or network packet flows. By monitoring these counts over time, CMS helps detect and alert administrators to potential security breaches or unusual activities in large-scale networks.
- Digital Advertising
- Application: Frequency Capping in Ads
- CMS is used in digital advertising to track how often a user sees a particular ad (frequency capping). It ensures that users do not get spammed with the same ads too frequently, helping advertisers control the exposure of ads while maintaining a good user experience.
- Machine Learning Feature Engineering
- Application: Tracking Feature Frequencies
- In large-scale machine learning systems, CMS can be used to track the frequency of feature occurrences in training data. This helps identify and select important features for model training, especially in text-based models or sparse datasets where frequency analysis is crucial for performance.
Other data structures
| Segment Tree | 1. Range Queries in Data Analysis (e.g., maximum/minimum) 2. Image Processing for dynamic pixel editing 3. Stock Price Monitoring 4. Game Development for hit detection 5. Time-Series Data Analysis |
| Fenwick Tree | 1. Cumulative Frequency Tables in Statistics 2. Real-time Data Analysis 3. Histogram Equalization in Image Processing 4. Event Counting in Games 5. Range Updates in Data Sets |
| B-Tree | 1. Database Indexing (e.g., MySQL) 2. File System Management (e.g., NTFS) 3. Storage in Flash Drives 4. Large Data Storage Systems 5. Multi-level Indexing in Databases |
| Suffix Tree | 1. Pattern Matching in Text (e.g., search engines) 2. DNA Sequence Analysis 3. Data Compression Techniques 4. Bioinformatics Applications 5. Plagiarism Detection |
| Disjoint Set (Union-Find) | 1. Network Connectivity Problems 2. Kruskal’s Algorithm for Minimum Spanning Trees 3. Image Segmentation in Computer Vision 4. Social Network Analysis 5. Dynamic Connectivity Queries |
| Red-Black Tree | 1. Database Indexing 2. In-memory Data Structures 3. Self-Balancing Trees in Libraries 4. Implementing Priority Queues 5. Data Management in Compilers |
| AVL Tree | 1. Memory Management Systems 2. Database Query Optimization 3. Managing Sorted Data in Real-Time 4. Search Applications 5. Implementing Fast Lookup Tables |
| Skip List | 1. Database Implementations for Search 2. Memory-Cached Systems 3. Efficiently Managing Sorted Data 4. Real-time Processing in Applications 5. Alternative to Balanced Trees |
| Treap | 1. Randomized Priority Queue 2. Memory Management Systems 3. Dynamic Sets in Real-Time Applications 4. Online Algorithms for Search Operations 5. Maintaining Order in Data Insertion |
| KD-Tree | 1. Nearest Neighbor Search in Machine Learning 2. Geographic Information Systems (GIS) 3. Game Development for Spatial Partitioning 4. Image Processing and Computer Graphics 5. Robotics Pathfinding |
| Quad Tree | 1. Spatial Data Representation (e.g., maps) 2. Image Compression Techniques 3. Collision Detection in Games 4. Geographic Information Systems 5. Environmental Monitoring Data Analysis |
| Van Emde Boas Tree | 1. Fast Predecessor Queries in Scheduling 2. Network Routing 3. Dynamic Set Operations in Real-time Applications 4. Time-sensitive Event Handling 5. Data Compression Algorithms |
| Suffix Array | 1. Full-text Search Algorithms 2. Data Compression Techniques 3. Bioinformatics for Pattern Matching 4. Text Processing in Natural Language Processing 5. DNA Sequence Matching |
Conclusion
In conclusion, data structures form the backbone of efficient algorithms and software applications, providing a means to manage and manipulate data in ways that closely mirror real-life problems. By understanding key structures like arrays, linked lists, stacks, queues, trees, graphs, and hash maps, developers can design solutions that are not only optimal but also scalable. Each data structure has its strengths and weaknesses, and knowing when and how to apply them in practical situations—from managing databases to optimizing search engines—is crucial for building robust systems. As technology continues to evolve, a solid grasp of data structures will remain indispensable, empowering both developers and businesses to handle complex data challenges more effectively.
1 thought on “Exploring Data Structures with Real-Life Applications”