
Consistent hashing is a technique used in distributed systems to evenly distribute data across a cluster of nodes, minimizing the amount of data that needs to be relocated when nodes are added or removed. This method ensures that the system remains scalable, fault-tolerant, and efficient.
Table of Contents
Introduction
In a large-scale distributed system, data does not fit on a single server. They are distributed across many machines. This is called horizontal scaling. To build such a system with predictable performance. It is important to distribute the data evenly across those servers.
A common method to distribute data as evenly as possible on servers is simple hashing
Server index = hash(key) % Nwhere N is the size of the server pool
First, for each object, we hash its keys with a hash function followed by a modulo operation to map the object to one of the servers from the available server pool.
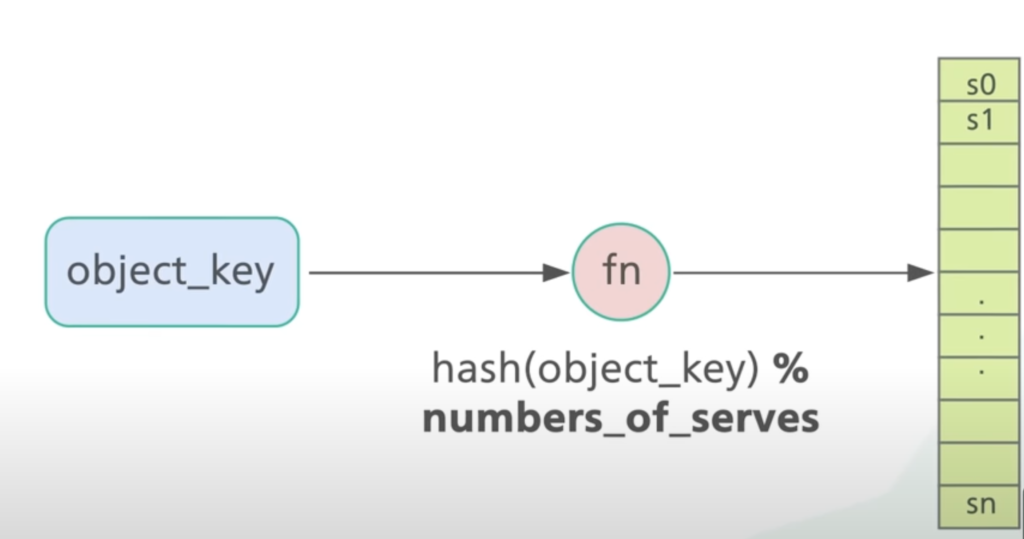
As long as the number of servers stays the same an object key will always map to the same server. But if there is any change in the number of servers, we need to redistribute almost all the object keys. This triggers a storm of data moments across the servers.
Consistent hashing is an effective technique to mitigate this issue.
What is Consistent Hashing?
Consistent hashing addresses this issue by minimizing the number of keys that need to be relocated when nodes are added or removed. It works by mapping both data and server to a continuous hash ring or circle.

Here’s how it functions:
- Hash Ring: Imagine a circle where hash values range from 0 to the maximum value of the hash function. Both server and data items are hashed to positions on this circle.
- Data Assignment: Each data item is assigned to the first server that appears clockwise from its position on the hash ring.
- Node Addition/Removal: When a node is added, it only affects the data items that map between the new server and its predecessor. When a node is removed, only the data items it was responsible for need to be reassigned.
Note: Consistent hashing, does depend on the number of servers. Hence changing the number of servers doesn’t have much effect live in simple hashing.
Mechanism of Consistent Hashing
To understand it in detail, consider the following steps:
- Hashing Nodes: Each node in the system is hashed to a position on the hash ring using a hash function.
- Hashing Data Items: Each data item is also hashed to a position on the hash ring using the same hash function.
- Mapping Data to Nodes: For a given data item, locate its position on the hash ring and assign it to the nearest node moving in the clockwise direction.
- Handling Node Changes:
- Node Addition: When a new node is added, it is hashed to a position on the hash ring. Only the data items between this new node and the next node clockwise are reassigned to the new node.
- Node Removal: When a node is removed, its data items are reassigned to the next node in the clockwise direction.
Virtual Nodes
A common enhancement to consistent hashing is the use of virtual nodes. Each physical node is assigned multiple virtual nodes, which are spread across the hash ring. This technique improves data load balancing and fault tolerance.
Practical Applications
Consistent hashing is widely used in various distributed systems, including:
- Distributed Databases: Systems like Apache Cassandra and Amazon DynamoDB use consistent hashing to distribute data across nodes, ensuring efficient data retrieval and fault tolerance.
- Content Delivery Networks (CDNs): Consistent hashing helps CDNs distribute content across servers, optimizing load distribution and reducing latency.
- Caching Systems: Memcached and similar caching systems use consistent hashing to distribute cached data across multiple servers, improving cache hit rates and scalability.
Cassandra uses consistent hashing.
Advantages of Consistent Hashing
- Scalability: Adding or removing nodes requires minimal data movement, enabling the system to scale efficiently.
- Load Balancing: Virtual nodes ensure a more even distribution of data, preventing hot spots.
- Fault Tolerance: Consistent hashing allows for seamless recovery from node failures, as only a small subset of data needs to be redistributed.
Conclusion
Consistent hashing is a powerful technique for managing distributed systems, providing an efficient and scalable method for data distribution. By minimizing data movement during node changes and using virtual nodes for better load balancing, consistent hashing ensures that distributed systems remain robust and performant. Understanding and implementing consistent hashing can significantly enhance the reliability and efficiency of your distributed applications.
1 thought on “Consistent Hashing: An In-Depth Guide”