SQL Window Functions are powerful tools that allow users to perform calculations across a set of table rows related to the current row.
Table of Contents
What is a Window Function?
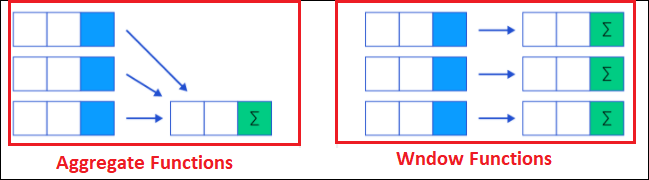
A window function performs a calculation across a set of table rows that are somehow related to the current row. This set of rows is referred to as the “window” and is defined using the OVER clause. Window functions are versatile and can be used for a wide range of analytical tasks.
Unlike aggregate functions, which return a single result for a group of rows, window functions can return multiple rows for each partition. This makes them incredibly useful for running totals, moving averages, and rank calculations.
Syntax
The general syntax for a window function is:
<function_name>(<expression>) OVER (
[PARTITION BY <expression>]
[ORDER BY <expression>]
[ROWS/RANGE BETWEEN <start> AND <end>]
)- <function_name>: The window function to be used (e.g., ROW_NUMBER, RANK, SUM, AVG).
- <expression>: The column or expression to be used in the function.
- PARTITION BY: Divides the result set into partitions to which the window function is applied.
- ORDER BY: Defines the order of the rows within each partition.
- ROWS/RANGE BETWEEN: Specifies the window frame for the function.
Common Window Functions

ROW_NUMBER()
The ROW_NUMBER function assigns a unique sequential integer to rows within a partition of a result set, starting at 1 for the first row in each partition.
SELECT employee_id,first_name, last_name, department_id, salary, ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY salary DESC) AS row_num FROM employees;Result:
| employee_id | first_name | last_name | department_id | salary | row_num |
|---|---|---|---|---|---|
| 2 | Jane | Smith | 1 | 6000 | 1 |
| 3 | Alice | Johnson | 1 | 5500 | 2 |
| 1 | John | Doe | 1 | 5000 | 3 |
| 5 | Charlie | Davis | 2 | 7000 | 1 |
| 6 | David | Wilson | 2 | 6000 | 2 |
| 4 | Bob | Brown | 2 | 4500 | 3 |
RANK() and DENSE_RANK()
The RANK function assigns a rank to each row within a partition, with gaps in the ranking values when there are ties. DENSE_RANK assigns ranks without gaps.
SELECT employee_id, first_name, last_name, department_id, salary, RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS rank, DENSE_RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS dense_rank FROM employees;Result:
| employee_id | first_name | last_name | department_id | salary | rank | dense_rank |
|---|---|---|---|---|---|---|
| 2 | Jane | Smith | 1 | 6000 | 1 | 1 |
| 3 | Alice | Johnson | 1 | 5500 | 2 | 2 |
| 1 | John | Doe | 1 | 5000 | 3 | 3 |
| 5 | Charlie | Davis | 2 | 7000 | 1 | 1 |
| 6 | David | Wilson | 2 | 6000 | 2 | 2 |
| 4 | Bob | Brown | 2 | 4500 | 3 | 3 |
SQL RANK() versus ROW_NUMBER()
- RANK and DENSE_RANK are deterministic, all rows with the same value for both the ordering and partitioning columns will end up with an equal result, whereas ROW_NUMBER will arbitrarily (non-deterministically) assign an incrementing result to the tied
- ROW_NUMBER: Returns a unique number for each row starting with 1. For rows that have duplicate values, numbers are arbitrarily assigned.
- Rank: Assigns a unique number for each row starting with 1, except for rows that have duplicate values, in which case the same ranking is assigned and a gap appears in the sequence for each duplicate ranking.
LAG() and LEAD()
The LAG function provides access to a row at a specified physical offset before the current row within the result set. LEAD does the same but for the row after the current row.
SELECT employee_id, first_name, last_name, department_id, salary, LAG(salary, 1) OVER (PARTITION BY department_id ORDER BY salary DESC) AS previous_salary, LEAD(salary, 1) OVER (PARTITION BY department_id ORDER BY salary DESC) AS next_salary FROM employees;Result:
| employee_id | first_name | last_name | department_id | salary | previous_salary | next_salary |
|---|---|---|---|---|---|---|
| 2 | Jane | Smith | 1 | 6000 | NULL | 5500 |
| 3 | Alice | Johnson | 1 | 5500 | 6000 | 5000 |
| 1 | John | Doe | 1 | 5000 | 5500 | NULL |
| 5 | Charlie | Davis | 2 | 7000 | NULL | 6000 |
| 6 | David | Wilson | 2 | 6000 | 7000 | 4500 |
| 4 | Bob | Brown | 2 | 4500 | 6000 | NULL |
Moving Average
Calculating a 2-salary moving average within each department.
SELECT employee_id, first_name, last_name, department_id, salary, AVG(salary) OVER (PARTITION BY department_id ORDER BY salary DESC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS moving_avg FROM employees;
Result:
| employee_id | first_name | last_name | department_id | salary | moving_avg |
|---|---|---|---|---|---|
| 2 | Jane | Smith | 1 | 6000 | 6000 |
| 3 | Alice | Johnson | 1 | 5500 | 5750 |
| 1 | John | Doe | 1 | 5000 | 5250 |
| 5 | Charlie | Davis | 2 | 7000 | 7000 |
| 6 | David | Wilson | 2 | 6000 | 6500 |
| 4 | Bob | Brown | 2 | 4500 | 5250 |
Cumulative Distribution
Calculating the cumulative distribution of salaries within each department.
SELECT employee_id, first_name, last_name, department_id, salary, CUME_DIST() OVER (PARTITION BY department_id ORDER BY salary) AS cum_dist FROM employees;Result:
| employee_id | first_name | last_name | department_id | salary | cum_dist |
|---|---|---|---|---|---|
| 1 | John | Doe | 1 | 5000 | 0.3333 |
| 3 | Alice | Johnson | 1 | 5500 | 0.6667 |
| 2 | Jane | Smith | 1 | 6000 | 1.0000 |
| 4 | Bob | Brown | 2 | 4500 | 0.3333 |
| 6 | David | Wilson | 2 | 6000 | 0.6667 |
| 5 | Charlie | Davis | 2 | 7000 | 1.0000 |
Conclusion
SQL Window Functions are incredibly powerful tools for performing complex calculations across a set of table rows related to the current row. By using the OVER clause, these functions can provide insights and analytics that are difficult to achieve with standard SQL queries. Understanding and leveraging these functions can greatly enhance your ability to perform data analysis and gain meaningful insights from your datasets.
Use the examples provided in this article to experiment with window functions and see how they can be applied to your specific use cases. With practice, you’ll be able to harness the full power of SQL Window Functions to perform advanced data analysis with ease.